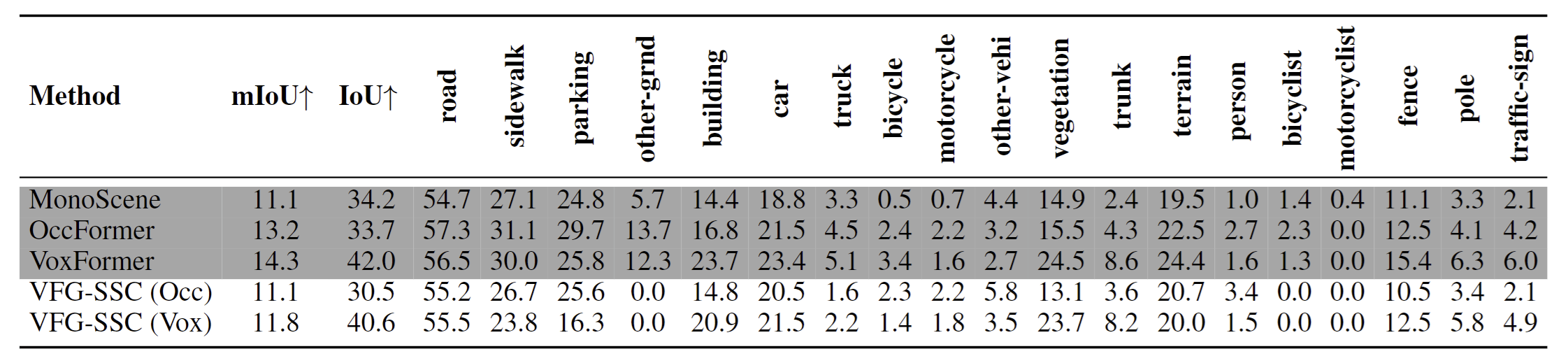
How it works
Semi-supervised Semantic Scene Completion (Semi-SSC) Formulation
Given a sequence $\mathbf{Q}_t = \{I_{t-k}, I_{t-k+1}\ldots, I_{t-1}, I_t \}$ of $k$ consecutive frames, the SSC model $f_\theta$ generates a semantic occupancy grid which is defined in the coordinate system of the ego vehicle at the timestamp $t$. Each voxel of the grid is categorized as either empty or occupied by a specific semantic class. The grid can be obtained as follows: $\mathbf{\hat{Y}}_t = f_\theta(\mathbf{Q_t})$ where $\mathbf{\hat{Y}}_t \in \mathbb{R}^{H \times W \times Z \times (C+1)}$. $H$, $W$, and $Z$ denote the voxel grid's height, width, and depth, and $C$ is the number of the semantic classes. In a semi-supervised setting (\Approach), the dataset contains two non-overlapping subsets:
- Labeled data $\mathcal{D}^L=\{(\mathbf{Q}_t, \mathbf{Y}_t)\}_{t=1}^L$ where each image $I_t$ has a corresponding 3D occupancy ground-truth $\mathbf{Y}_t$.
- Unlabeled data $\mathcal{D}^U = \{\mathbf{Q}_t\}_{t=1}^U$, which only contains images with \textbf{no LiDAR} and the amount of the unlabeled data is significantly larger than labeled data, i.e, $U \gg L$.
VFG-SSC pipeline
A common strategy for tackling the semi-supervised problem is Self-Training. This involves first training a supervised model $f_\theta$ on labeled data $\mathcal{D}^L$ and then generating pseudo-labels for the unlabeled dataset $\mathcal{D}^U$. After that, the model $f_\theta$ is retrained using both the labeled and pseudo-labeled data. Based on this Self-Training approach, our key contribution is to enhance the quality of the pseudo-label by incorporating 3D priors extracted from 2D vision foundation models. We now outline our three-step process in detail.
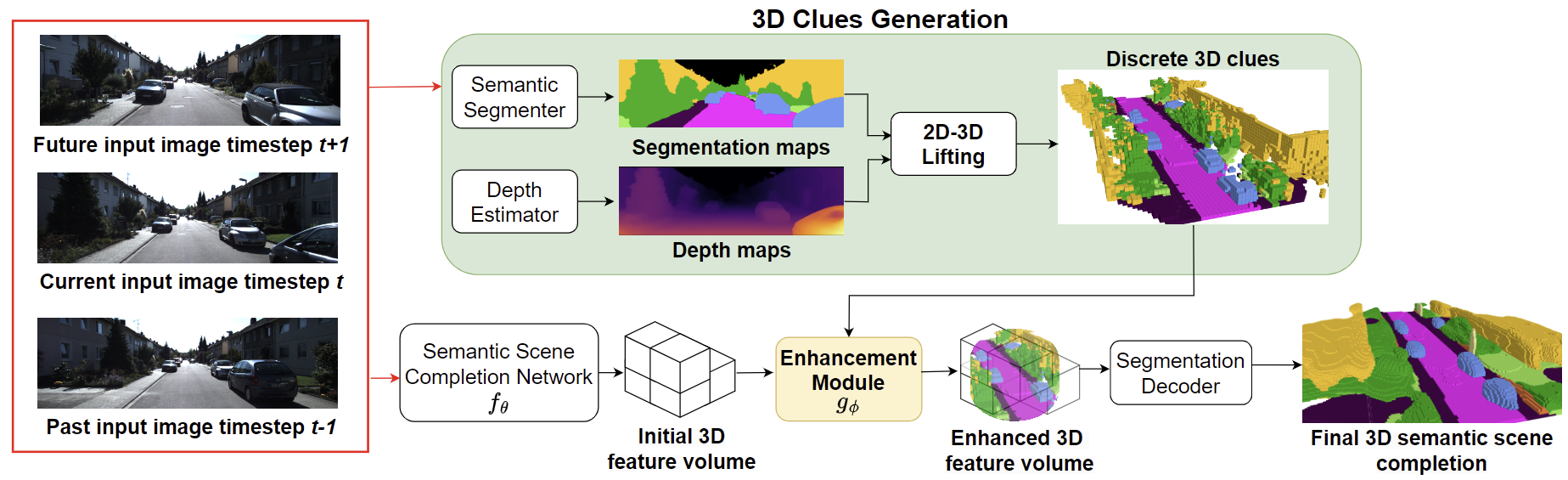
Comparison with other methods
Quantitative comparison of VFG-SSC with SOTA metric depth estimators on several zero-shot benchmarks. Our VFG-SSC significantly outperforms baseline methods. Remarkably, our approach achieves comparable results to fully supervised counterparts, with just a 15% performance gap using 10% labeled data.
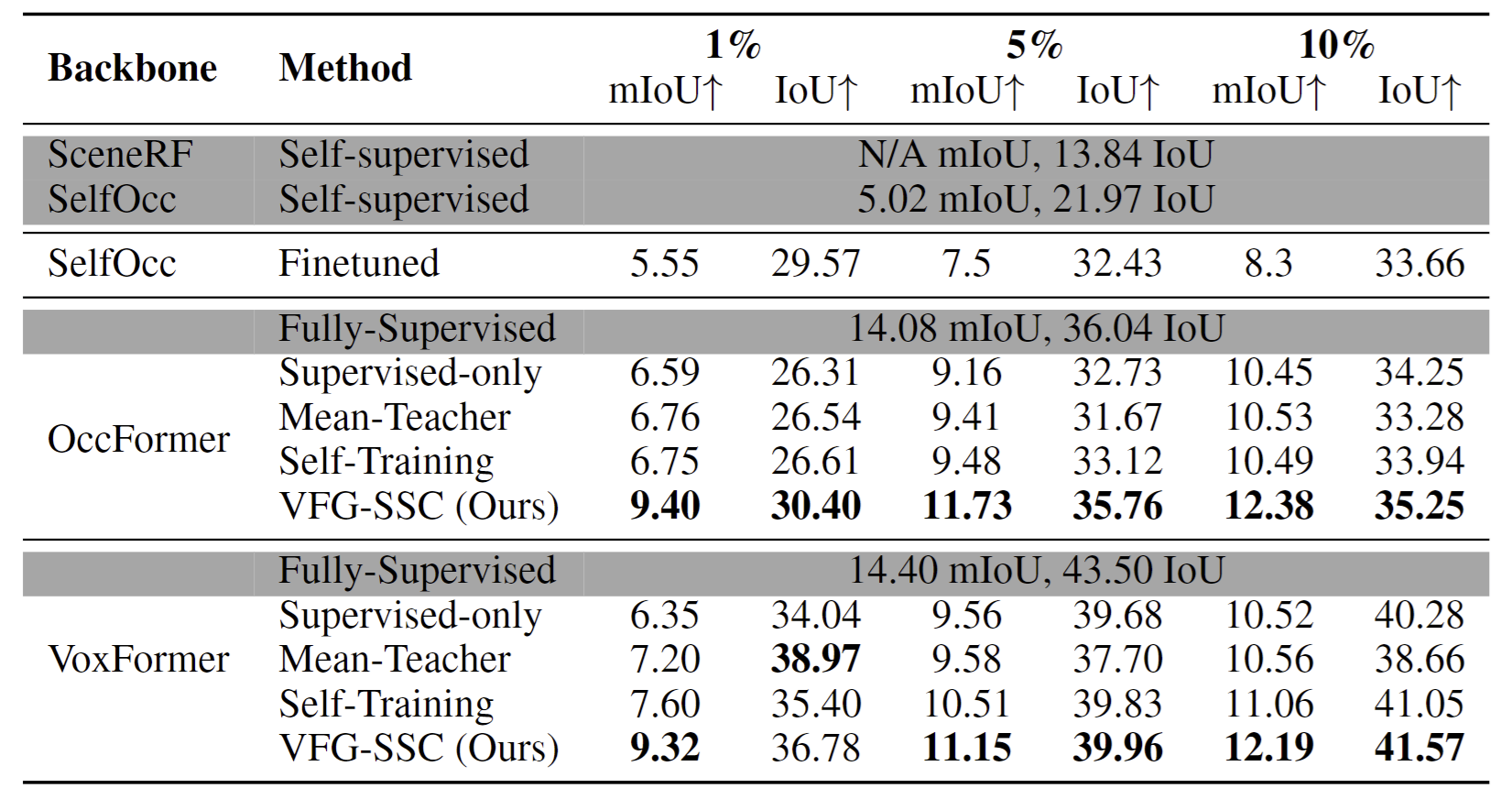
For NYUv2, we consistently outperform other methods with both 5\% and 10\% of training data, underscoring the superiority of our approach over strong baselines. These results indicate that our VFG-SSC is generalizable to different architectures, can be applied to various labeled settings, and applies to both outdoor and indoor scenarios.
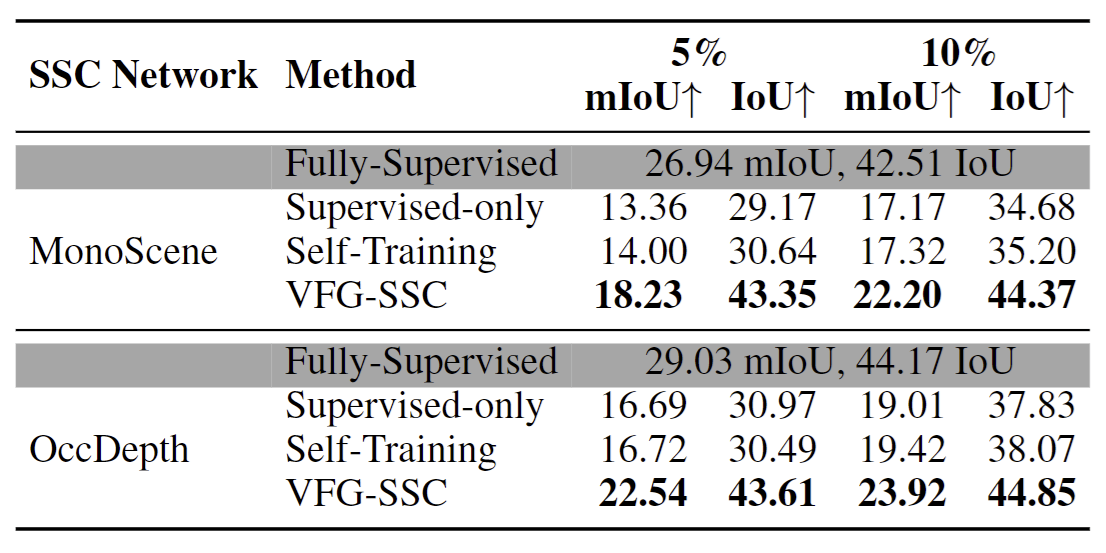
Moreover, on the SemanticKITTI hidden test set, our method compares favorably with some fully supervised methods like MonoScene, despite utilizing only 10% labeled occupancy annotation. This emphasizes the effectiveness of our 3D clues and enhancement module, which is effective in generating high-quality pseudo-labels for training any SSC backbones.